Chapter 02: logistic-regression Model¶
1. Introduction¶
Solomon and Wynne conducted an experiment on Dogs in 1953 . They wanted to understand, whether Dogs can learn from mistakes, so to speak. Specifically, they were interested in avoidance-learning. That is, when Dogs are given trauma-inducing shocks, will they learn to avoid shocks in future?
We can state the objectives of the expeirment, according to our understanding, in more general terms as follows:
Can the Dogs learn?
Can they retain & recollect what they learnt?
The experimental setup, to drive the objectives, holds a dog in a closed compartment with steel flooring, open on one side with a small barrier for dog to jump over to the other side. A high-voltage electric shock is discharged into the steel floor intermittently to stimulate the dog. The dog is then left with an option to either get the shock for that trial or jump over the barrier to the other side & save himself. Several dogs were recruited in the experiment.
The following picture (source) is an illustration of the setup.
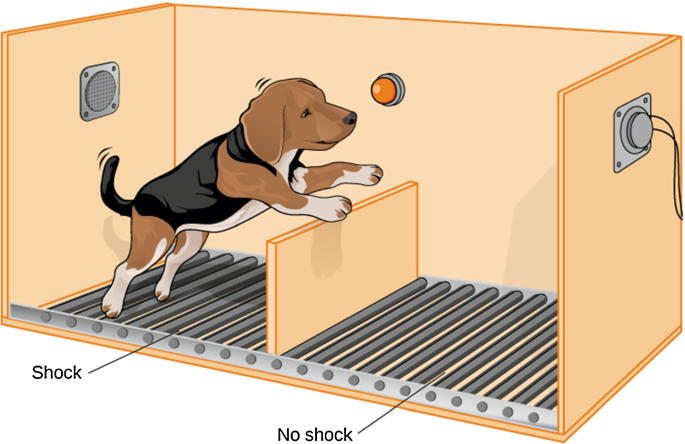
More details of the experiment can be found here.
{kind=link}
In this chapter, we will re-analyze the experimental data using Bayesian Analysis, and the inference will be carried out in Pyro.
Recapitulating, we want to model the relationship between avoidance-in-future and past-traumatic-experiences . The following log-linear model is a starting point:
\(\pi_j = A^{xj} B^{j-xj} \)
where :
\(\pi_j\) is the probability of a dog getting shocked at trial \(j\).
\(x_j\) is number of successful avoidances of shock prior to trial \(j\).
\(j-x_j\) is number of shocks experienced prior to trial \(j\).
A & B, both are unknown and treated as random variables.
However, instead of using an exp link function as we did in the previous chapter, we will use a sigmoid link function. Time for some boilder plate and preliminary EDA.
import torch
import pyro
import pandas as pd
import itertools
from collections import defaultdict
import matplotlib.pyplot as plt
import pyro.distributions as dist
import seaborn as sns
import plotly
import plotly.express as px
import plotly.figure_factory as ff
from chapter02 import base
import numpy as np
pyro.set_rng_seed(10)
plt.style.use('default')
%matplotlib inline
%load_ext autoreload
Data¶
The data contains experiments over 30 dogs and each dog is subjected to 25 trials.
The plot that follows highlights Dogs data in dictionary format, averaged over dog population for each trial, i.e., \(y_j = \frac{1}{30}\sum{y_{ij}}\) where \(y_{ij}\) is the i-th Dog’s response at the j-th trial.
dogs_data = base.load_data()
base.plot_original_y(1-np.mean(dogs_data["Y"], axis=0), ylabel='Probability of shock at trial j', mode_type="lines+markers")
Its apparent from experimental data that more than half the dog population learns to avoid shocks in trials as few as 5, and also that the learning doesn’t significantly rise with increased number of trials.
Preprocessing¶
Next, we need to transform raw data to obtain:
x_avoidance: number of shock avoidances before current trial.x_shocked: number of shocks before current trial.y: status ‘shocked (y=1) or avoided(y=0)’ at current trial.
Here pystan format data (python dictionary) is passed to the function above, in order to preprocess it to the tensor format required for pyro sampling.
x_avoidance, x_shocked, y = base.transform_data(**dogs_data)
print("x_avoidance: %s, x_shocked: %s, y: %s"%(x_avoidance.shape, x_shocked.shape, y.shape))
print("\nSample x_avoidance: %s \n\nSample x_shocked: %s"%(x_avoidance[1], x_shocked[1]))
base.plot_original_y(x_avoidance.numpy(), ylabel='Cumulative Avoidances', mode_type="lines+markers")
base.plot_original_y(x_shocked.numpy(), ylabel='Cumulative Shocked Trials', mode_type="lines+markers")
x_avoidance: torch.Size([30, 25]), x_shocked: torch.Size([30, 25]), y: torch.Size([30, 25])
Sample x_avoidance: tensor([0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 1., 1., 1., 2., 2., 3.])
Sample x_shocked: tensor([ 0., 1., 2., 3., 4., 5., 6., 7., 8., 8., 9., 10., 11., 12.,
13., 14., 15., 16., 17., 18., 19., 20., 20., 21., 21.])
The original data is not revealing much; looking at the cumulative avoidances and shocks, we see that some dogs never learn (example: Dog 1-4), and some dogs learn and retain the learning behaviour (example: Dog 25-30).
2. Model Specification¶
The sampling distrution of the generative model, as indicated earlier, is:
\(y_{ij} \sim Bern(\pi_{ij})\)
\(\pi_{ij} = \sigma(\alpha x_{ij} + \beta({j-x_{ij}}))\)
Here, \(y_{ij}=1\) if the a dog fails to avoid a shock at the j-th trial, and is 0 if it avoids. Further, \(\sigma(x) = \frac{1}{1 - e^{-x}}\), is the usual sigmoid function.
We elicit normal priors for \(\alpha,\beta\) with zero mean and large variance (flat) to complete the specification. Also notice that, the above model is in a more familiar form (Generalized Linear Model or Log-Linear Model). For convenience, we can define \(X_{a}\equiv x_{ij}, X_{s}\equiv j-x_{ij} \)
The complete model is:
\(y_{ij} \sim Bern(\pi_{ij})\)
\(\pi_{ij} = \sigma( \alpha X_{a} + \beta X_{s})\)
\(\alpha \sim N(0., 316.)\)
\(\beta \sim N(0., 316.)\)
Unlike in chapter 01 we experiment with the slight variations of the above models as follow:
Model A.
\(y_{ij} \sim Bern(\pi_{ij})\)
\(\pi_{ij} = \sigma (\alpha X_{a} + \beta X_{s})\)
\(\alpha \sim N(0., 316.)\)
\(\beta \sim N(0., 316.)\)
Model B.
\(y_{ij} \sim Bern(\pi_{ij})\)
\(\pi_{ij} = \sigma(\alpha X_{a} + \beta X_{s})\)
\(\alpha \sim U(-30.78, 30.78)\)
\(\beta \sim U(-30.78, 30.78)\)
The above expression is used as a generalised linear model with logisitc-link function in WinBugs implementation
Model implementation¶
The above models are defined in base.DogsModel
DogsModel= base.DogsModel
DogsModel
<function chapter02.base.DogsModel(x_avoidance, x_shocked, y, alpha_prior=None, beta_prior=None, activation='exp')>
Let us also draw few samples from the prior, and look at the distribution
num_samples = 1100
alpha_prior_a, beta_prior_a= base.init_priors({"default":dist.Normal(0., 316.)})# Pass Normal priors for model A
prior_samples_a = base.get_prior_samples(alpha_prior_a, beta_prior_a, num_samples=num_samples)
alpha_prior_b, beta_prior_b= base.init_priors({"default":dist.Uniform(-30.78,30.78)})# Pass uniform priors for model B
prior_samples_b = base.get_prior_samples(alpha_prior_b, beta_prior_b, num_samples=num_samples)
Sampled output of prior values for \(\alpha\) & \(\beta\) are stored in prior_samples above, and are plotted on a KDE plot as follows:
base.plot_prior_distributions(model_normal_a= prior_samples_a, model_uniform_b= prior_samples_b)
For model 'model_normal_a' Prior alpha Q(0.5) :13.435971736907959 | Prior beta Q(0.5) :22.337939262390137
For model 'model_uniform_b' Prior alpha Q(0.5) :1.1585655212402344 | Prior beta Q(0.5) :0.5592708587646484
3. Prior Predictive Checking¶
Prior predictive checking (PiPC)
original_plus_simulated_prior_data = base.simulate_observations_given_prior_posterior_pairs(dogs_data["Y"], num_dogs=30, num_trials=24,
activation_type= "sigmoid", model_normal_a= prior_samples_a,
model_uniform_b= prior_samples_b)
___________
For model 'model_normal_a' prior
total samples count: 1100 sample example: [(-190.04013061523438, -319.8582763671875), (-95.51708221435547, -387.94891357421875)]
/Users/tachyon/Desktop/p3/Part_II/Chapter_2/chapter02.py:259: RuntimeWarning:
overflow encountered in exp
Total execution time: 78.11382412910461
Number of datasets/prior pairs generated: 1100
Shape of data simulated from prior for model 'model_normal_a' : (25,)
___________
For model 'model_uniform_b' prior
total samples count: 1100 sample example: [(-9.30595588684082, 20.834199905395508), (-22.897798538208008, -16.99627113342285)]
Total execution time: 76.54441094398499
Number of datasets/prior pairs generated: 1100
Shape of data simulated from prior for model 'model_uniform_b' : (25,)
Respective shape of original data: (25,) and concatenated arrays of data simulated for different priors/posteriors: (3, 25)
_______________________________________________________
______________________________________________________________________
Here 'Dog_1' corresponds to observations simulated from prior of 'model_normal_a', 'Dog_2' corresponds to observations simulated from prior of 'model_uniform_b' & 'Dog_3' corresponds to 'Original data'.
Even though the mean and median can differ from run to run, looking at the densities, the variance is vary large – so the sample mean would also have huge variance. The take-away is that, both \(\alpha, \beta\) are given very weak priors. We more or less rely on the data (evidence) to drive their estimation.
TBD: Prior Sensitivity Analysis
4. Posterior Estimation¶
In the Bayesian setting, inference is drawn from the posterior. Here, posterior implies the updated beliefs about the random variables, in the wake of given evidences (data). Formally,
\(Posterior = \frac {Likelihood x Prior}{Probability \ of Evidence}\)
In our case, \(\alpha,\beta\) are the parameters (actually random variables) & \(y\) is the evidence; According to the Bayes rule, Posterior \(P(\alpha,\beta | y)\) is given as:
\(P\ (\alpha,\beta | y) = \frac {P(y | \alpha,\beta) \pi(\alpha,\beta)}{P(y)}\)
Now our interest is in estimating the posterior summaries of the parameters \(\alpha, \beta\). For example, we can look at the posterior of mean of \(\alpha\), denoted as \(E(\alpha)\). However, in order to the get the posterior quanitities, either we need to compute the integrals or approximate the integrals via Markov Chain Monte Carlo.
The latter can be easily accomplished in Pyro by using the NUTS sampler – NUTS is a specific sampler designed to draw samples efficiently from the posterior using Hamiltonian Monte Carlo dynamics.
The following code snippet takes a pyro model object with – posterior specification, input data, some configuration parameters such as a number of chains and number of samples per chain. It then launches a NUTS sampler and produces MCMC samples in a python dictionary format.
# DogsModel_A alpha, beta ~ Normal(0, 316.) & activation "sigmoid"
hmc_sample_chains_a, hmc_chain_diagnostics_a = base.get_hmc_n_chains(DogsModel, x_avoidance, x_shocked, y,
num_chains=4, sample_count = 900, burnin_percentage= 0.2,
alpha_prior= dist.Normal(0., 316.),
beta_prior= dist.Normal(0., 316.), activation= "sigmoid")
Sample: 100%|██████████| 13500/13500 [00:56, 239.43it/s, step size=6.27e-01, acc. prob=0.934]
Sample: 100%|██████████| 13500/13500 [00:50, 265.48it/s, step size=6.97e-01, acc. prob=0.910]
Sample: 100%|██████████| 13500/13500 [01:00, 221.45it/s, step size=5.32e-01, acc. prob=0.953]
Sample: 100%|██████████| 13500/13500 [00:49, 272.89it/s, step size=7.40e-01, acc. prob=0.908]
Total time: 218.51996493339539
# DogsModel_1B alpha, beta ~ Uniform(-30.78,30.78) & activation "sigmoid"
hmc_sample_chains_b, hmc_chain_diagnostics_b = base.get_hmc_n_chains(DogsModel, x_avoidance, x_shocked, y,
num_chains=4, sample_count = 900, burnin_percentage= 0.4,
alpha_prior= dist.Uniform(-30.78,30.78),
beta_prior= dist.Normal(-30.78, 30.78), activation= "sigmoid")
Sample: 100%|██████████| 21000/21000 [01:36, 216.62it/s, step size=5.86e-01, acc. prob=0.905]
Warmup: 6%|▌ | 755/13500 [1:05:13, 5.18s/it, step size=6.04e-06, acc. prob=0.765]]
Warmup: 13%|█▎ | 2090/16714 [54:18, 1.56s/it, step size=3.37e-06, acc. prob=0.778]
Sample: 100%|██████████| 21000/21000 [19:38, 17.81it/s, step size=6.37e-01, acc. prob=0.886]
Sample: 100%|██████████| 21000/21000 [01:46, 196.50it/s, step size=4.88e-01, acc. prob=0.936]
Sample: 100%|██████████| 21000/21000 [4:45:51, 1.22it/s, step size=5.25e-01, acc. prob=0.925]
Total time: 18536.32725596428
hmc_sample_chains holds sampled MCMC values as {"Chain_0": {alpha [-0.20020795, -0.1829252, -0.18054989 . .,], "beta": {}. .,}, "Chain_1": {alpha [-0.20020795, -0.1829252, -0.18054989 . .,], "beta": {}. .,}. .}
5. MCMC Diagnostics¶
Diagnosing the computational approximation
Just like any numerical technique, no matter how good the theory is or how robust the implementation is, it is always a good idea to check if indeed the samples drawn are reasonable. In the ideal situation, we expect the samples drawn by the sampler to be independant, and identically distributed (i.i.d) as the posterior distribution. In practice, this is far from true as MCMC itself is an approximate technique and a lot can go wrong. In particular, chains may not have converged or samples are very correlated. We can divide diagnosis into three sections.
Burn-in: What is the effect of initialization? By visually inspecting the chains, we can notice the transient behaviour. We can drop the first “n” number of samples from the chain.
Thinning: What is the intra chain correlation? We can use ACF (Auto-correlation function) to inspect it. A rule of thumb is, thin the chains such that, the ACF drops to \(1/10^{th}\). Here, ACF drops to less than 0.1 at lag 5, then we retain only every \(5^{th}\) sample in the chain.
Mixing: Visually, all the chains, when plotted, should be indistinguishable from each other. At a very broad level, the means of the chains and variances shall be close. These are the two central moments we can track easily and turn them into Gelman-Rubin statistic. Other summmary statistics can be tracked, of course.
We can use both visual and more formal statistical techniques to inspect the quality of the fit (not the model fit to the data, but how well the approximation is, having accepted the model class for the data at hand) by treating chains as time-series data, and that we can run several chains in parallel. We precisely do that next.
Following snippet allows plotting Parameter vs. Chain matrix and optionally saving the dataframe.
Model-A Summaries¶
# Unpruned sample chains for model A with Normal prior
beta_chain_matrix_df_A = pd.DataFrame(hmc_sample_chains_a)
base.save_parameter_chain_dataframe(beta_chain_matrix_df_A, "data/dogs_parameter_chain_matrix_2A.csv")
Saved at 'data/dogs_parameter_chain_matrix_2A.csv'
A.1 Visual summary¶
A.1.1 Intermixing chains¶
Sample chains mixing for Normal priors.
Following plots chains of samples for alpha & beta parameters for model_normal_a
base.plot_chains(beta_chain_matrix_df_A)
for chain, samples in hmc_sample_chains_a.items():
print("____\nFor model_Normal_a %s"%chain)
samples= dict(map(lambda param: (param, torch.tensor(samples.get(param))), samples.keys()))# np array to tensors
print(chain, "Sample count: ", len(samples["alpha"]))
print("Alpha Q(0.5) :%s | Beta Q(0.5) :%s"%(torch.quantile(samples["alpha"], 0.5), torch.quantile(samples["beta"], 0.5)))
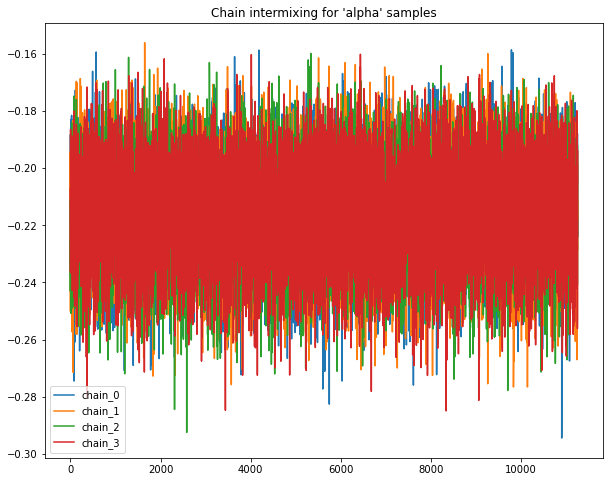
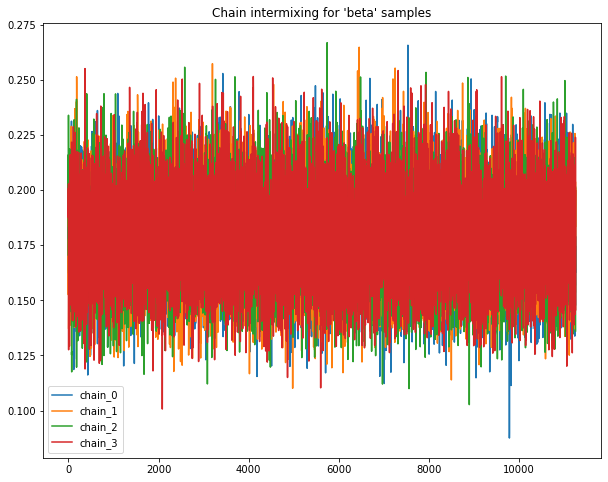
____
For model_Normal_a chain_0
chain_0 Sample count: 11250
Alpha Q(0.5) :tensor(-0.2158) | Beta Q(0.5) :tensor(0.1790)
____
For model_Normal_a chain_1
chain_1 Sample count: 11250
Alpha Q(0.5) :tensor(-0.2158) | Beta Q(0.5) :tensor(0.1792)
____
For model_Normal_a chain_2
chain_2 Sample count: 11250
Alpha Q(0.5) :tensor(-0.2151) | Beta Q(0.5) :tensor(0.1784)
____
For model_Normal_a chain_3
chain_3 Sample count: 11250
Alpha Q(0.5) :tensor(-0.2153) | Beta Q(0.5) :tensor(0.1790)
A.2 Quantitative summary¶
A.2.1 ACF plots¶
Auto-correlation plots for sample chains with Normal priors
base.autocorrelation_plots(beta_chain_matrix_df_A)
For alpha, thining factor for chain_0 is 7, chain_1 is 7, chain_2 is 7, chain_3 is 7
for beta, thinin factor for chain_0 is 7, chain_1 is 7, chain_2 is 7, chain_3 is 7
Pruning chains from model with Normal priors
thining_dict_a = {"chain_0": {"alpha":7, "beta":7}, "chain_1": {"alpha":7, "beta":7},
"chain_2": {"alpha":7, "beta":7}, "chain_3": {"alpha":7, "beta":7}}
pruned_hmc_sample_chains_a = base.prune_hmc_samples(hmc_sample_chains_a, thining_dict_a)
-------------------------
Original sample counts for 'chain_0' parameters: {'alpha': (11250,), 'beta': (11250,)}
Thining factors for 'chain_0' parameters: {'alpha': 7, 'beta': 7}
Post thining sample counts for 'chain_0' parameters: {'alpha': (1607,), 'beta': (1607,)}
-------------------------
Original sample counts for 'chain_1' parameters: {'alpha': (11250,), 'beta': (11250,)}
Thining factors for 'chain_1' parameters: {'alpha': 7, 'beta': 7}
Post thining sample counts for 'chain_1' parameters: {'alpha': (1607,), 'beta': (1607,)}
-------------------------
Original sample counts for 'chain_2' parameters: {'alpha': (11250,), 'beta': (11250,)}
Thining factors for 'chain_2' parameters: {'alpha': 7, 'beta': 7}
Post thining sample counts for 'chain_2' parameters: {'alpha': (1607,), 'beta': (1607,)}
-------------------------
Original sample counts for 'chain_3' parameters: {'alpha': (11250,), 'beta': (11250,)}
Thining factors for 'chain_3' parameters: {'alpha': 7, 'beta': 7}
Post thining sample counts for 'chain_3' parameters: {'alpha': (1607,), 'beta': (1607,)}
A.2.2 G-R statistic¶
Gelman-Rubin statistic for chains with Normal priors
grubin_values_a = base.gelman_rubin_stats(pruned_hmc_sample_chains_a)
Gelmen-rubin for 'param' alpha all chains is: 0.9997
Gelmen-rubin for 'param' beta all chains is: 0.9995
A.3 Descriptive summary¶
Following outputs the summary of required statistics such as "mean", "std", "Q(0.25)", "Q(0.50)", "Q(0.75)", select names of statistic metric from given list to view values.
A.3.1 Summary Table 1¶
Tabulated Summary for model chains with Normal priors
#chain results Pruned after ACF plots
beta_chain_matrix_df_A = pd.DataFrame(pruned_hmc_sample_chains_a)
base.summary(beta_chain_matrix_df_A)
Select any value
We can also report the 5-point Summary Statistics (mean, Q1-Q4, Std, ) as tabular data per chain and save the dataframe
fit_df_A = pd.DataFrame()
for chain, values in pruned_hmc_sample_chains_a.items():
param_df = pd.DataFrame(values)
param_df["chain"]= chain
fit_df_A= pd.concat([fit_df_A, param_df], axis=0)
base.save_parameter_chain_dataframe(fit_df_A, "data/dogs_classification_hmc_samples_2A.csv")
Saved at 'data/dogs_classification_hmc_samples_2A.csv'
Use following button to upload:
"data/dogs_classification_hmc_samples_2A.csv"as'fit_df_A'
# Use following to load data once the results from pyro sampling operation are saved offline
load_button= base.build_upload_button()
# Use following to load data once the results from pyro sampling operation are saved offline
if load_button.value:
fit_df_A = base.load_parameter_chain_dataframe(load_button)#Load "data/dogs_classification_hmc_samples_2A.csv"
A.3.2 Summary Table 2¶
5-point Summary Statistics for model chains with Normal priors
Following outputs the similar summary of required statistics such as "mean", "std", "Q(0.25)", "Q(0.50)", "Q(0.75)", but in a slightly different format, given a list of statistic names
base.summary(fit_df_A, layout =2)
Select any value
Following plots sampled parameters values as Boxplots with M parameters side by side on x axis for each of the N chains.
Pass the list of M parameters and list of N chains, with plot_interactive as True or False to choose between Plotly or Seaborn
A.4 Additional plots¶
A.4.1 Boxplots¶
Boxplot for model chains with Normal priors
parameters= ["alpha", "beta"]# All parameters for given model
chains= fit_df_A["chain"].unique()# Number of chains sampled for given model
# Use plot_interactive=False for Normal seaborn plots offline
base.plot_parameters_for_n_chains(fit_df_A, chains=['chain_0', 'chain_1', 'chain_2', 'chain_3'], parameters=parameters, plot_interactive=True)
A.4.2 Joint distribution plots¶
Following plots the joint distribution of pair of each parameter sampled values for all chains with Normal priors.
base.plot_joint_distribution(fit_df_A, parameters)
# #
Pyro -- alpha Vs. beta
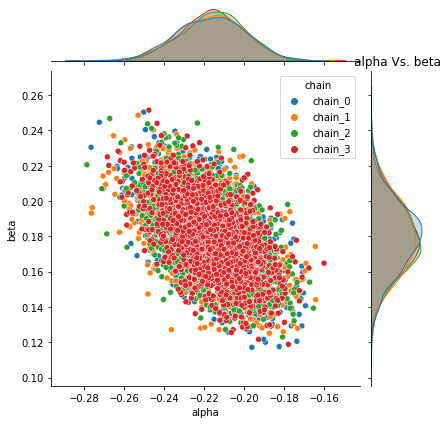
A.4.3 Pairplots¶
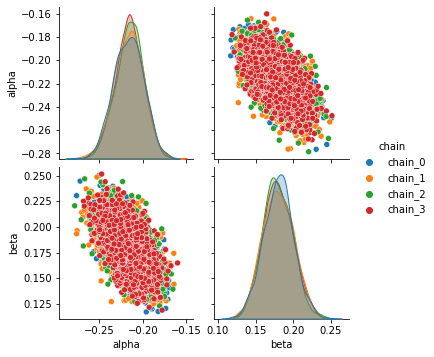
Following plots the Pairplot distribution of each parameter with every other parameter’s sampled values for all chains with Normal priors
sns.pairplot(data=fit_df_A, hue= "chain");
Model-B Summaries¶
# Unpruned sample chains for model B with Uniform prior
beta_chain_matrix_df_B = pd.DataFrame(hmc_sample_chains_b)
base.save_parameter_chain_dataframe(beta_chain_matrix_df_B, "data/dogs_parameter_chain_matrix_2B.csv")
Saved at 'data/dogs_parameter_chain_matrix_2B.csv'
B.1 Visual summary¶
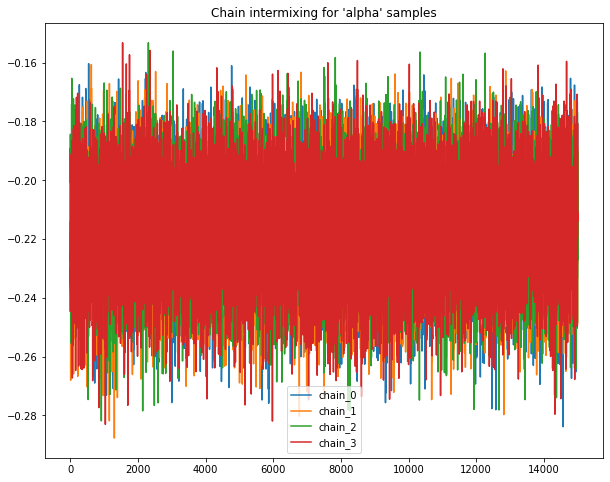
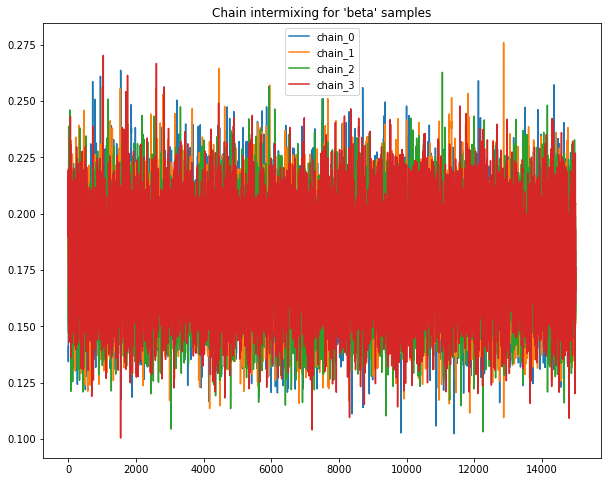
B.1.1 Intermixing chains¶
Sample chains mixing for Uniform priors.
Following plots chains of samples for alpha & beta parameters for model_Uniform_b
base.plot_chains(beta_chain_matrix_df_B)
for chain, samples in hmc_sample_chains_b.items():
print("____\nFor model_Uniform_b %s"%chain)
samples= dict(map(lambda param: (param, torch.tensor(samples.get(param))), samples.keys()))# np array to tensors
print(chain, "Sample count: ", len(samples["alpha"]))
print("Alpha Q(0.5) :%s | Beta Q(0.5) :%s"%(torch.quantile(samples["alpha"], 0.5), torch.quantile(samples["beta"], 0.5)))
____
For model_Uniform_b chain_0
chain_0 Sample count: 15000
Alpha Q(0.5) :tensor(-0.2157) | Beta Q(0.5) :tensor(0.1790)
____
For model_Uniform_b chain_1
chain_1 Sample count: 15000
Alpha Q(0.5) :tensor(-0.2155) | Beta Q(0.5) :tensor(0.1788)
____
For model_Uniform_b chain_2
chain_2 Sample count: 15000
Alpha Q(0.5) :tensor(-0.2155) | Beta Q(0.5) :tensor(0.1785)
____
For model_Uniform_b chain_3
chain_3 Sample count: 15000
Alpha Q(0.5) :tensor(-0.2157) | Beta Q(0.5) :tensor(0.1798)
B.2 Quantitative summary¶
B.2.1 ACF plots¶
Auto-correlation plots for sample chains with Uniform priors
base.autocorrelation_plots(beta_chain_matrix_df_B)
For alpha, thining factor for chain_0 is 7, chain_1 is 7, chain_2 is 7, chain_3 is 7
for beta, thinin factor for chain_0 is 7, chain_1 is 7, chain_2 is 7, chain_3 is 7
Pruning chains from model with Uniform priors
thining_dict_b = {"chain_0": {"alpha":7, "beta":7}, "chain_1": {"alpha":7, "beta":7},
"chain_2": {"alpha":7, "beta":7}, "chain_3": {"alpha":7, "beta":7}}
pruned_hmc_sample_chains_b = base.prune_hmc_samples(hmc_sample_chains_b, thining_dict_b)
-------------------------
Original sample counts for 'chain_0' parameters: {'alpha': (15000,), 'beta': (15000,)}
Thining factors for 'chain_0' parameters: {'alpha': 7, 'beta': 7}
Post thining sample counts for 'chain_0' parameters: {'alpha': (2143,), 'beta': (2143,)}
-------------------------
Original sample counts for 'chain_1' parameters: {'alpha': (15000,), 'beta': (15000,)}
Thining factors for 'chain_1' parameters: {'alpha': 7, 'beta': 7}
Post thining sample counts for 'chain_1' parameters: {'alpha': (2143,), 'beta': (2143,)}
-------------------------
Original sample counts for 'chain_2' parameters: {'alpha': (15000,), 'beta': (15000,)}
Thining factors for 'chain_2' parameters: {'alpha': 7, 'beta': 7}
Post thining sample counts for 'chain_2' parameters: {'alpha': (2143,), 'beta': (2143,)}
-------------------------
Original sample counts for 'chain_3' parameters: {'alpha': (15000,), 'beta': (15000,)}
Thining factors for 'chain_3' parameters: {'alpha': 7, 'beta': 7}
Post thining sample counts for 'chain_3' parameters: {'alpha': (2143,), 'beta': (2143,)}
B.2.2 G-R statistic¶
Gelman-Rubin statistic for chains with Uniform priors
grubin_values_b = base.gelman_rubin_stats(pruned_hmc_sample_chains_b)
Gelmen-rubin for 'param' alpha all chains is: 0.9996
Gelmen-rubin for 'param' beta all chains is: 0.9996
B.3 Descriptive summary¶
Following outputs the summary of required statistics such as "mean", "std", "Q(0.25)", "Q(0.50)", "Q(0.75)", select names of statistic metric from given list to view values
B.3.1 Summary Table 1¶
Tabulated Summary for model chains with Uniform priors
#chain results Pruned after ACF plots
beta_chain_matrix_df_B = pd.DataFrame(pruned_hmc_sample_chains_b)
base.summary(beta_chain_matrix_df_B)
Select any value
We can also report the 5-point Summary Statistics (mean, Q1-Q4, Std, ) as tabular data per chain and save the dataframe
fit_df_B = pd.DataFrame()
for chain, values in pruned_hmc_sample_chains_b.items():
param_df = pd.DataFrame(values)
param_df["chain"]= chain
fit_df_B= pd.concat([fit_df_B, param_df], axis=0)
base.save_parameter_chain_dataframe(fit_df_B, "data/dogs_classification_hmc_samples_2B.csv")
Saved at 'data/dogs_classification_hmc_samples_2B.csv'
Use following button to upload:
"data/dogs_classification_hmc_samples_2B.csv"as'fit_df_B'
# Use following to load data once the results from pyro sampling operation are saved offline
load_button= base.build_upload_button()
# Use following to load data once the results from pyro sampling operation are saved offline
if load_button.value:
fit_df_B= base.load_parameter_chain_dataframe(load_button)#Load "data/dogs_classification_hmc_samples_2B.csv"
B.3.2 Summary Table 2¶
5-point Summary Statistics for model chains with Uniform priors
Following outputs the similar summary of required statistics such as "mean", "std", "Q(0.25)", "Q(0.50)", "Q(0.75)", but in a slightly different format, given a list of statistic names
base.summary(fit_df_B, layout =2)
Select any value
Following plots sampled parameters values as Boxplots with M parameters side by side on x axis for each of the N chains.
Pass the list of M parameters and list of N chains, with plot_interactive as True or False to choose between Plotly or Seaborn
B.4 Additional plots¶
B.4.1 Boxplots¶
Boxplot for model chains with Uniform priors
parameters= ["alpha", "beta"]# All parameters for given model
chains= fit_df_B["chain"].unique()# Number of chains sampled for given model
# Use plot_interactive=False for Normal seaborn plots offline
base.plot_parameters_for_n_chains(fit_df_B, chains=['chain_0', 'chain_1', 'chain_2', 'chain_3'], parameters=parameters, plot_interactive=True)
B.4.2 Joint distribution plots¶
Following plots the joint distribution of pair of each parameter sampled values for all chains with Uniform priors.
base.plot_joint_distribution(fit_df_B, parameters)
Pyro -- alpha Vs. beta
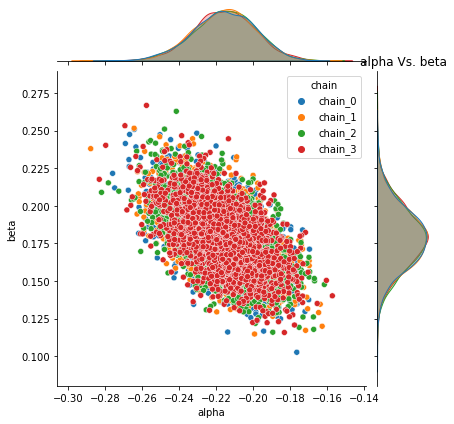
B.4.3 Pairplots¶
Following plots the Pairplot distribution of each parameter with every other parameter’s sampled values for all chains with Uniform priors
sns.pairplot(data=fit_df_B, hue= "chain");
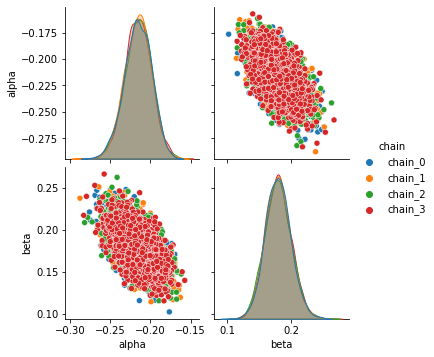
Combined KDE plots¶
Kernel density plots for model_Normal_a & model_Uniform_b
for chain in hmc_sample_chains_a.keys():
print("____\nFor 'model_Normal_a' & 'model_Uniform_b' %s"%chain)
chain_list= list(hmc_sample_chains_a[chain].values())
chain_list.extend(list(hmc_sample_chains_b[chain].values()))
title= "parameter distribution for : %s"%(chain)
fig = ff.create_distplot(chain_list, ["alpha_a", "beta_a", "alpha_b", "beta_b"])
fig.update_layout(title=title, xaxis_title="parameter values", yaxis_title="density", legend_title="parameters")
fig.show()
break
____
For 'model_Normal_a' & 'model_Uniform_b' chain_0
Statsmodel logistic-regression¶
Fit a statsmodel logistic regression for \(\pi_{ij}\) as another alternate reference model to obtain the estimates of \(\alpha\ and\ \beta \) in frequentist paradigm.
data_df= pd.DataFrame({"avoided":np.sum(dogs_data["Y"], axis=1), "shocks":dogs_data["Ntrials"]- np.sum(dogs_data["Y"], axis=1)})
data_df["Pij"]= np.round(1-np.mean(dogs_data["Y"], axis=1))
data_df.head(5)
| avoided | shocks | Pij | |
|---|---|---|---|
| 0 | 0 | 25 | 1.0 |
| 1 | 3 | 22 | 1.0 |
| 2 | 2 | 23 | 1.0 |
| 3 | 2 | 23 | 1.0 |
| 4 | 6 | 19 | 1.0 |
import statsmodels.api as sm
Xtrain= data_df[["avoided", "shocks"]]
ytrain= data_df[["Pij"]]
# log_reg = sm.Logit(ytrain, Xtrain).fit()
The above fit sm.Logit(ytrain, Xtrain).fit() outputs -
PerfectSeparationError: Perfect separation detected, results not available.
It imples that there is no unique alpha-beta pair that fits the data; Infact there are infinite plausible pairs of alpha, beta parameters which can be decisive in parting data along the lines of ‘shocked vs. avoided’.
Nothing unusual seems to be happening.
All chains are mixing well (G-R statistics are close to 1).
ACF of the chains decay rapidly.
Both
NormalandUniformare giving similar resultsBut, joint distribution of \(\alpha, \beta\) has strong correlation, and is consistent across chains.
Let us do Posterior Predictive checks
6. Sensitivity Analysis¶
Posterior Predictive Checking (PoPC) helps examine the fit of a model to real data. The simulation parameters come from the posterior distribution. While PoPC incorporates model uncertainly (by averaging over all possible models), we take a simpler route to begin with, which is to sample the \(\alpha, \beta\) pairs that are very plausible in the posterior (eg. the posterior means), and simulate data under this particular generative model.
In particular, just like the PiPC (Prior Predictive Check), we are intereted in the posterior expected value of a Dog getting shocked. This quantity can be estimated by the Monte Carlo average:
where \(\alpha_t, \beta_t\) are the t-th posterior samples in the MCMC chain.
# With priors & posteriros
posterior_parameters_pairs_a = pruned_hmc_sample_chains_a.get('chain_0')
posterior_parameters_pairs_b = pruned_hmc_sample_chains_b.get('chain_0')
original_plus_simulated_data_posterior = base.simulate_observations_given_prior_posterior_pairs(dogs_data["Y"],
num_dogs=30, num_trials=24, activation_type= "sigmoid",
prior_simulations= original_plus_simulated_prior_data,
model_normal_a= posterior_parameters_pairs_a,
model_uniform_b= posterior_parameters_pairs_b)
___________
For model 'model_normal_a' posterior
total samples count: 1607 sample example: [(-0.20771554, 0.16250883), (-0.1965488, 0.18346697)]
Total execution time: 110.77076888084412
Number of datasets/posterior pairs generated: 1607
Shape of data simulated from posterior for model 'model_normal_a' : (25,)
___________
For model 'model_uniform_b' posterior
total samples count: 2143 sample example: [(-0.18443489, 0.1410535), (-0.2114582, 0.1672326)]
Total execution time: 950.3785030841827
Number of datasets/posterior pairs generated: 2143
Shape of data simulated from posterior for model 'model_uniform_b' : (25,)
Respective shape of original data: (25,) and concatenated arrays of data simulated for different priors/posteriors: (5, 25)
_______________________________________________________
______________________________________________________________________
Here 'Dog_1' corresponds to observations simulated from posterior of 'model_normal_a', 'Dog_2' corresponds to observations simulated from posterior of 'model_uniform_b', 'Dog_3' corresponds to observations simulated from prior of 'model_normal_a', 'Dog_4' corresponds to observations simulated from prior of 'model_uniform_b' & 'Dog_5' corresponds to 'Original data'.
Observation:
From the Posterior predictive plots, it is evident that model estimates stay at around 0.5 and largely indecisive to answer if the dogs learn or not. Since we used sigmoid link function this time, the possible reason for the observed behaviour could be due to negative correlation between \(\alpha\) & \(\beta\). So, for minor differences between \(x_a,x_s\), the logists remain close to 0.
Also with the current specification of link function and prior distribution it seems the posterior estimates may converge after excessively large number of trials (i.e. what if we have collected not 25 but 100 trials).
Save simulated data from prior & posterior predictive checking
original_plus_simulated_data_posterior_df= pd.DataFrame(original_plus_simulated_data_posterior.T,
columns=["Dog_%s"%(idx+1) for idx in range(len(original_plus_simulated_data_posterior))])
base.save_parameter_chain_dataframe(original_plus_simulated_data_posterior_df,
"data/dogs_original_plus_simulated_data_model_2ab.csv")
Saved at 'data/dogs_original_plus_simulated_data_model_2ab.csv'
Compare existing models model_Normal_A & model_Uniform_B with models 1A & 1B from chapter 01.
# Load data from PiPC & PoPC for model_1A & 1B simulations
load_button= base.build_upload_button()
# Load data from PiPC & PoPC for model_1A & 1B simulations
if load_button.value:
original_plus_simulated_data_posterior_model_1_df = base.load_parameter_chain_dataframe(load_button)#Load "../chapter_01/data/dogs_original_plus_simulated_data_model_1ab.csv"
else:
original_plus_simulated_data_posterior_model_1_df = pd.read_csv("../chapter_01/data/dogs_original_plus_simulated_data_model_1ab.csv")
original_plus_simulated_data_posterior_model_1 = original_plus_simulated_data_posterior_model_1_df.values.T
combined_original_plus_simulated_data_model_1_2 = np.concatenate([original_plus_simulated_data_posterior[:-1], original_plus_simulated_data_posterior_model_1])
# Uncomment following & run this cell to load the "combined_original_plus_simulated_data_model_1_2" in case loss of state
# combined_original_plus_simulated_data_model_1_2 = pd.read_csv("data/dogs_original_plus_simulated_data_model_1ab_2ab_combined.csv").values.T
print("Shape of model 1 & 2 combined array: ", combined_original_plus_simulated_data_model_1_2.shape)
ylabel_text= 'Probability of shock at trial j [original & priors, posteriors]'
print("\n\nHere\n'Dog_1': observations from 'model_normal_a Posterior'.\n'Dog_2' : observations from 'model_uniform_b Posterior'.\
\n'Dog_3': observations from 'model_normal_a Prior'.\n'Dog_4': observations from 'model_uniform_b Prior'\n%s"%("_"*55))
print("\nHere\n'Dog_5': observations from 'model_HalfNormal_1a Posterior'. \n'Dog_6' : observations from 'model_uniform_1b Posterior'.\
\n'Dog_7' : observations from 'model_HalfNormal_1a Prior'. \n'Dog_8' : observations from 'model_uniform_1b Prior'.\
\n\n'Dog_9': observations from 'Original data'.")
base.plot_original_y(combined_original_plus_simulated_data_model_1_2, ylabel=ylabel_text, mode_type="lines+markers")
Shape of model 1 & 2 combined array: (9, 25)
Here
'Dog_1': observations from 'model_normal_a Posterior'.
'Dog_2' : observations from 'model_uniform_b Posterior'.
'Dog_3': observations from 'model_normal_a Prior'.
'Dog_4': observations from 'model_uniform_b Prior'
_______________________________________________________
Here
'Dog_5': observations from 'model_HalfNormal_1a Posterior'.
'Dog_6' : observations from 'model_uniform_1b Posterior'.
'Dog_7' : observations from 'model_HalfNormal_1a Prior'.
'Dog_8' : observations from 'model_uniform_1b Prior'.
'Dog_9': observations from 'Original data'.
combined_original_plus_simulated_data_model_1_2_df= pd.DataFrame(combined_original_plus_simulated_data_model_1_2.T,
columns=["Dog_%s"%(idx+1) for idx in range(len(combined_original_plus_simulated_data_model_1_2))])
base.save_parameter_chain_dataframe(combined_original_plus_simulated_data_model_1_2_df,
"data/dogs_original_plus_simulated_data_model_1ab_2ab_combined.csv")
Saved at 'data/dogs_original_plus_simulated_data_model_1ab_2ab_combined.csv'
7. Model Comparison¶
More often than not, there may be many plausible models that can explain the data. Sometime, the modeling choice is based on domain knowledge. Sometime it is out of comptational conveninece. Latter is the case with the choice of priors. One way to consider different models is by eliciting different prior distributions.
As long as the sampling distribtion is same, one can use Deviance Information Criterion (DIC) to guide model comparison.
DIC¶
DIC(Deviance Information Criterion) is computed as follows
\(D(\alpha,\beta) = -2\ \sum_{i=1}^{n} \log P\ (y_{i}\ /\ \alpha,\beta)\)
\(\log P\ (y_{i}\ /\ \alpha,\beta)\) is the log likehood of shocks/avoidances observed given parameter \(\alpha,\beta\), this expression expands as follows:
Using $D(\alpha,\beta)$ to Compute DIC
\(\overline D(\alpha,\beta) = \frac{1}{T} \sum_{t=1}^{T} D(\alpha,\beta)\)
\(\overline \alpha = \frac{1}{T} \sum_{t=1}^{T}\alpha_{t}\\\) \(\overline \beta = \frac{1}{T} \sum_{t=1}^{T}\beta_{t}\)
Therefore finally
Following method computes deviance value given parameters `alpha & beta`
#launch docstring for calculate_deviance_given_param
#launch docstring for calculate_mean_deviance
Following method computes deviance information criterion for a given bayesian model & chains of sampled parameters alpha & beta
#launch docstring for DIC
#launch docstring for compare_DICs_given_model
Sample an alternate model with different priors
The alternate model is defined in the same manner using Pyro as per the following expression of generative model for this dataset, just with modification of prior distribution to Uniform rather than Normal as follows:
Instead of considering Normal priors of \(\alpha\) and \(\beta\), we consider uniform priors, i.e., \(prior\ \alpha\) ~ \(U(-30.79, 30.79)\), \(\beta\) ~ \(U(-30.79, 30.79)\)
In Section 5., we already sampled such model to obtain posterior chains as pruned_hmc_sample_chains_b which we shall use for computing DIC in cells that follow.
compute & compare deviance information criterion for a multiple bayesian models
base.compare_DICs_given_model(x_avoidance, x_shocked, y, Dogs_Normal_prior= pruned_hmc_sample_chains_a, Dogs_uniform_prior= pruned_hmc_sample_chains_b)
______________________________
For model : Dogs_Normal_prior
. . .DIC for chain_0: 473.076
. . .DIC for chain_1: 473.187
. . .DIC for chain_2: 472.776
. . .DIC for chain_3: 472.891
. .Mean Deviance information criterion for all chains: 472.982
______________________________
For model : Dogs_uniform_prior
. . .DIC for chain_0: 472.985
. . .DIC for chain_1: 472.915
. . .DIC for chain_2: 472.848
. . .DIC for chain_3: 472.895
. .Mean Deviance information criterion for all chains: 472.911
The DIC values are very close, so we don’t anticipate substantially different fits. This is largely because, both priors are flat. However, if we were to follow the rule book, we had to pick a model with the smallest DIC. In this case, we can go Uniform Priors, but differences need not be substantial with Normal Priors
8. Inference & Analysis¶
Alright, we have a model, but so what? The purpose of model building is to use these models as probing devices. That is, using the models can we answer some questions about the reality that these models have abstracted.
We choose model with Normal Prior, and pick samples from one particular chain of HMC samples say chain_3
for chain, samples in pruned_hmc_sample_chains_a.items():
samples= dict(map(lambda param: (param, torch.tensor(samples.get(param))), samples.keys()))# np array to tensors
print(chain, "Sample count: ", len(samples["alpha"]))
chain_0 Sample count: 1607
chain_1 Sample count: 1607
chain_2 Sample count: 1607
chain_3 Sample count: 1607
Plot density for parameters from chain_3 to visualise the spread of sample values from that chain
title= "parameter distribution for : %s"%(chain)
fig = ff.create_distplot(list(map(lambda x:x.numpy(), samples.values())), list(samples.keys()))
fig.update_layout(title=title, xaxis_title="parameter values", yaxis_title="density", legend_title="parameters")
fig.show()
print("Alpha Q(0.5) :%s | Beta Q(0.5) :%s"%(torch.quantile(samples["alpha"], 0.5), torch.quantile(samples["beta"], 0.5)))
Alpha Q(0.5) :tensor(-0.2160) | Beta Q(0.5) :tensor(0.1786)
Plot density & contours for both parameters from chain_3 to visualise the joint distribution & region of interest with Normal priors.
#Choosing samples from chain 3
chain_samples_df_A= fit_df_A[fit_df_A["chain"]==chain].copy()# chain is 'chain_3'
alpha= chain_samples_df_A["alpha"].tolist()
beta= chain_samples_df_A["beta"].tolist()
colorscale = ['#7A4579', '#D56073', 'rgb(236,158,105)', (1, 1, 0.2), (0.98,0.98,0.98)]
fig = ff.create_2d_density(alpha, beta, colorscale=colorscale, hist_color='rgb(255, 255, 150)', point_size=4, title= "Alpha-Beta joint density plot for model with 'Normal' prior")
fig.update_layout( xaxis_title="x (alpha)", yaxis_title="y (beta)")
fig.show()
Observations:¶
On observing the joint distribution of \(\alpha, \beta\), we note that
\(\beta > \alpha\),
\(\alpha, \beta\) are negatively correlated.
\(|\alpha|-|\beta| << 1\)
Here, \(\beta\) can be interpreted as learning ability, i.e., the ability of a dog to learn from shock experiences, and \(\alpha\) as the rention ability.
print(chain_samples_df_A["alpha"].describe(),"\n\n", chain_samples_df_A["beta"].describe())
count 1607.000000
mean -0.216290
std 0.015919
min -0.268298
25% -0.226395
50% -0.215999
75% -0.205768
max -0.160231
Name: alpha, dtype: float64
count 1607.000000
mean 0.179386
std 0.020168
min 0.118849
25% 0.165354
50% 0.178597
75% 0.193389
max 0.251477
Name: beta, dtype: float64
From the contour plot above following region in posterior distribution seems highly plausible for parameters:
For alpha,
-0.22 < alpha < -0.20For beta
0.16 < beta < 0.19
Since, \(\alpha\) is always negative, let us look at \(\frac{|\alpha|}{|\beta|}\) as a proxy to see which of the two (learning ability and _retention_ability) are domimant.
We are using \(\frac{|\alpha|}{|\beta|}\) as a probing device to answer that question, and similar quantities can be defined. With MCMC samples available, we can get posterior probabilties of any function of the model parameters (here \(\alpha, \beta\). Say, we can be interested in the \(E(\frac{|\alpha|}{|\beta|})\) or \(P(\frac{|\alpha|}{|\beta|}<1)\).
The latter quantity can be estimate by the Monte Carlo average as follows: \(P(\frac{|\alpha|}{|\beta|}>1) = \frac{1}{n}\sum_{t=1}^{n} I(|\alpha| < |\beta|)\), i.e, the fraction of times \(\alpha < \beta\).
Or, we can look at the distribution of \(\frac{|\alpha|}{|\beta}\)
# Uncomment to load model_normal_A chains
# chain_samples_df_A = pd.read_csv("data/dogs_classification_hmc_samples_2A.csv")
x1 = np.abs(chain_samples_df_A["alpha"].to_numpy())
x2 = np.abs(chain_samples_df_A["beta"].to_numpy())
p = np.mean(x1<x2)
print(p)
_= plt.hist(x1-x2, bins=40)
0.01851275668948351
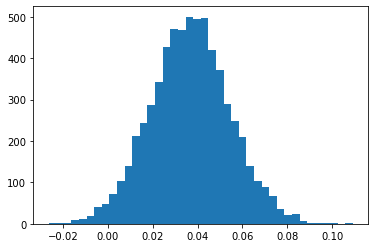
But we look at probablity \(P(|\alpha|-|\beta|>0)\) is greater than 0.8. But \(\alpha, \beta\) are not different from a practical significance standpoint (how much of a difference will cause changes in \(\pi_{ij}\) as \(P(|\alpha|-|\beta|>0.08) > 0.8\), roughly speaking. This observations makes the point about statistical significance vs practical significance, when making decisions.
Is this (causing the logits to be very close 0, implying avoidance learning is pretty much random? Or was this a simply modeling error?
9. Commentary¶
Using
sigmoidas link function fits the data better, compared toexplink. ThePiPCandPoPCdid follow conventional wisdom that posterior lies between data and prior.As a result of natural centering of the priors around zero,
pyrosampler should not have problem.Still, the posterior was close to prior than to the original data; This could be due to inherent strucure of the modeling.
We did notice moderate-to-strong negative posterior correlation between \(\alpha\) and \(\beta\). This is expected since the covariates themselves are negatively correlated; Therefore its an artifact of the model itself, not because of the data. This indciates that, we could have reparamitrized the model better.
Overall, it was a better model than the model with
explink function. However, we can not useDICto compare the models with different link functions, because, fundamentally, the likelihoods are different. Then, the constant term in the DIC, which is often omitted when comparing models with same likelihoods, cannot be ignoredThe same data when fit using plain logistic regression,
statsmodeldetected a perfect seperation. This is not obvious in the Bayesian setting. Therefore, its always a good idea to run frequentist methods, wherever possible, to get a sense of the estimates.The posterior evidence was inconclusive for whether Dogs learn from their mistakes or not. It could be an artifact of the modeling choice.
10. Exercises¶
If two models, one with
expand another withsigmoidlinks are to be compared, argue whyDICcannot be used. If using DIC is problematic, which other metrics can be used?Derive the expression for DIC in the above model.
As the number of trials increase, what happens to prior and posterior expectation of shocks, at the last trial? Does it decreases? If yes, at what rate?
Is flat prior same as non-informative prior in this case?
Show that the above model is a Bayesian logistic regression model and its equivalence is exact under improper priors.
When \(|\frac{\alpha}{\beta}| \approx 1\), under what conditions, Dogs learning behaviour is random?
In retrospect, the way covariates are specfied, and model structure is elicited, is leading to spurious outcomes. Based on analysis from ch01 and ch02, what are better alternatives? Which reparametrization is recommended in this case?